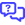Explaining the Inverse Chain and Investigating Large Recovery Points
This article explains the Datto Inverse Chain, and how it differs from the traditional incremental chain.
Environment 
- Datto SIRIS
- Datto ALTO
- Datto NAS
- Datto Cloud
Incremental Chain
The traditional incremental backup chain consists of a full backup file, followed by a chain of incremental image files. This has some drawbacks:
- Although there are ways to compress this chain, it may grow too long for practical management.
- If a single incremental file is lost or corrupted, then the chain is no longer viable.
The Datto Inverse Chain
The Datto Inverse Chain allows for:
- greater compression.
- rolling retention.
- deletion of recovery points from anywhere in the chain without interfering with integrity.
- instant recovery from any given point in the chain.
The chain can be seen as a rolling base chain. The initial full backup, or base image, resides at the bottom, with the other points in the chain housing incremental changes (snapshots) for each point in time. A change shared by multiple points resides only in the oldest point in which it occurs; the newer points merely reference that original point.
This means each point holds the data needed to restore to that moment in time, while the actual data being restored resides in an older point. The original data change information will not be removed until all snapshots referencing it are removed. Because of this, any snapshot in the chain can be removed without affecting the integrity of the remaining snapshots.
Example 
Three backups are taken: An initial full backup Monday, an incremental backup Tuesday, and an incremental backup Wednesday.
- The oldest point contains the initial state of the machine.
- The point from Tuesday contains the first incremental changes.
- Wednesday's point refers to, but does not itself contain, the changes between the initial backup and the changes made Tuesday. It only contains the unique data changes made between the second and third backups.
The Inverse Chain in Action
Datto's inverse chain technology starts off with a full backup to obtain the initial dataset.
Agent-based and Agentless protected systems
- This initial full backup is converted into thin-provisioned virtual disks, also referred to as sparse images.
- A ZFS snapshot is taken of the sparse image, and it is committed to the backup chain in a non-bootable state (It will be made bootable if a restore is brought up.)
- Subsequent incremental backups write the block level changes in data, and ZFS snapshots of those virtual disks are taken, committing the changes.
NAS and iSCSI shares
- For NAS and iSCSI shares, this process is essentially the same, but the snapshot is taken of the state of the dataset, not the virtual disks.
- ZFS is not concerned with the files and folders specifically, but the state of the dataset as a whole.
- Any additions, modifications or file removals since the last snapshot are recorded.
Synchronization
When it is time to send data offsite, the device will first check for existing connecting points that allow it to add the new data to the offsite chain. These are the last two points to sync offsite.
- If the device finds connecting points, it will build a send file containing the incremental changes between the newer connecting point and the one currently set to go offsite. The offsite backup chain is like the local chain, except instead of taking backups, we are sending a file containing the incremental difference between the last connecting point and the most recent one
- If there are no connecting points to reference, such as when a new backup chain is started, or when the connecting points are removed to free up space, the device will build a send file containing that recovery point and its full base image.
Misconceptions
Local Space: When a point is removed, it only frees the amount of data change contained within that point that is also not referenced later in the chain. The data amount reported in Remote Web is the total amount of data needed to create the recovery point, not the total amount of data actually written to that point. Data existing in newer points will roll up, all the way up to the most recent snapshot if applicable. Some compression is available as well on unencrypted agents.
Incremental Backup: If a protected server experiences an unexpected shutdown or severe backup writer conflict, the next incremental backup may be so divergent from the recorded backup chain that it cannot be reconciled. In this situation the chain must be restarted with a new full backup or a differential merge (preferred). If this is detected the backup may run as a differential merge by default to continue backups without user intervention.
Ransomware: Datto backup chains are not susceptible to ransomware attacks. In the event that a machine protected by Datto's agent-based or agentless solution is infected by ransomwarere, restoration is still possible from a point in time prior to the ransomware attack at any time. If a protected machine backs itself up while a ransomware infection is present in the production environment, Datto's ransomware detection feature will alert you to the presence of malware in the snapshot taken. You can then safely remove it from the backup chain without compromising the integrity of any other snapshots.
Determining amount of space used
The best indicator of total space used is on the Home page, under Local Storage. Note that the "Total Protected" number under Device Information indicates the total original size of all protected volumes.
The Local Storage Usage listing shows the total size of each agent volume, including the size of the original volume plus the used space added by maintaining recovery point snapshots.
Causes of large recovery points: Block/Sector Level Change and Journaling Disruption
Block/sector level change
For backup chains of agents, large, full-image-sized recovery points as seen in the 'Access Recovery Points' view may sometimes be Differential Merges.
New Full Backup vs. Differential Merge
If a new full backup was taken, the total space used by the Agent will be approximately double the original size of a full image of all included volumes (as set in Advanced Options). In the case of a Differential Merge, a recovery point the size of a full backup is displayed, but the total used space does not dramatically increase.
If a reboot of the protected machine is triggered as the result of a Windows update, the next backup will be a Differential Merge.
For Windows agents, if a system consistently requires differential merges, there is likely a block-level or VSS-related issue which may eventually require a new full backup. Agentless backups having this issue may be having issues with their Change Block Tracker (CBT). Unclean shutdowns of the agent are another cause across all OS types.
Volume Shadow Service (VSS)
Often the cause of large recovery points on Windows agents is found by checking running services against conflicting services (such as those found in the VSS Explained article). These services can often upset the Datto Windows Agent incremental journaling, so that it must run a differential merge to find where the last incremental left off.
Disk Defragmentation
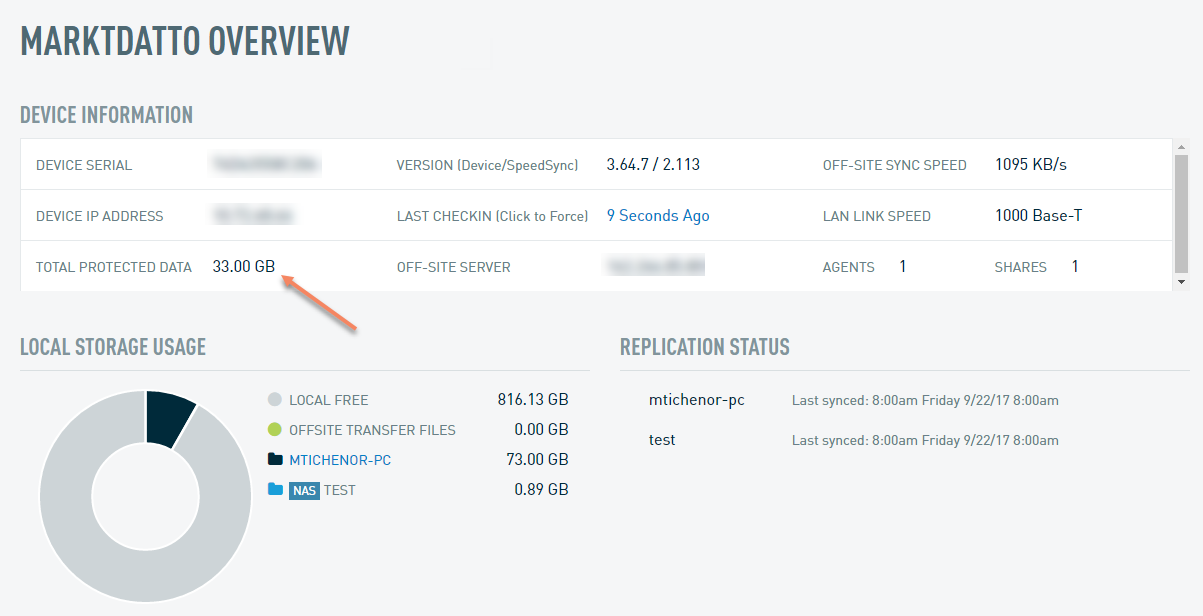
In Windows, evidence may exist on the protected system's System Event Log of disk defragmentation or other maintenance taking place during a backup. Also, there might be previous or ongoing disk failure, previous system failure, or unexpected shutdown. These events may generate so much block level change that a normal incremental will never reconcile with the original backup chain.
Please note that block-level changes due to defragmentation or checkdisk operations may be disproportionately large, as the repair of each block may imply changes to multiple blocks on the disk.
Causes of Large Block/Sector Level Data Change
SQL Logging Issues
If you are backing up a volume used to store SQL backups, SQL or Exchange logs, or other backups of the system that would be redundant with Datto backups. you are backing that database up twice.
The data change used by redundant backups can multiply if backups are also being deleted, as both the deletion and the new backup will register as change. This is true across OS types.
Volume Shadow Copies
In Windows, running Volume Shadow Copies and storing them on a volume imaged by Datto Windows Agent has the same effect as other backups. If Volume Shadow Storage is near capacity this may also delete old backups as it makes new ones, multiplying the block-level change detected.
Database Defragmentation
Defragmenting large databases also causes large block-level change. it is important to avoid taking backups during defragmentation, as subsequent incremental backups will have difficulty matching the chain and a Differential Merge or new full backup may be necessary.
Virtual Machines
In a hypervisor environment, backup snapshots of guest OS systems stored on a volume backed up by an agent-based solution can generate large block level change, or trigger differential merges. With agentless backups, the backup process leverages VMwareÂ’s snapshot process, so it should not be used elsewhere.
SAN-hosted Storage
Sparsely or dynamically allocated SAN-hosted storage is not recommended, and backups of these volumes tend to be large and difficult to recover data from, as normal incremental journaling has difficulty tracking dynamically allocated blocks. Data stored on sparse or dynamic SAN hosts should be backed up at a file level to a NAS share on the Datto device using NAS Guard.
Distributed File System (DFS)
When running DFS, files get staged in a temp folder while awaiting transmission over the network. This can result in large block level change. If DFS is domain-dependent, make sure to supply the correct domain credentials to allow the transfers to occur. Also, set it up with a path that the source service can reach. Even when you set it up according to these standards, you may still experience large block level change. As an alternative to sharing, try RDC.
Inverse Chain Mechanics and Managing New Full Backups
If a new full backup is taken, the backup chain replaces the previous full backup within the chain, and future incremental snapshots will reference the new full backup. This means, after a full backup, two backup chains will exist within the one actual chain. When this happens, space usage essentially doubles as each chain has its own base and historical incrementals.
In order to fully reduce the space used by multiple full backups, all recovery points associated with old full backups must be deleted, leaving only the points from the most recent backup onward, or remove everything from the new full up to the most recent recovery point (the latter is not advised). These situations can lead to a device with full storage.
It is possible to roll back a new full backup, but whether the agent software can generate a new incremental that reconciles into the original chain depends on the extent of the change the agent software is reading on the volume. When this is attempted, be sure to prompt a Differential Merge from the Agent's Advanced Options.
Our Differential Merge technology makes it possible to reconcile a backup chain with a changed volume in many cases that would otherwise require a new full image. However, maintaining a stable backup chain remains a concern for any incremental backup solution.
Maintenance of the protected machine, its disks, and in the case of Windows its VSS writers, including an up-to-date OS, are the main avenues to preventing issues with large recovery points.